I'll
Give You a Definite Maybe
An Introductory Handbook on
Probability, Statistics, and Excel
[This handbook has been prepared by Ian Johnston of Malaspina University-College for students in Liberal Studies. This text is in the public domain, released May 2000, and may be used, in whole or in part, without charge and without permission, by anyone]
For comments, suggestions, corrections, improvements, and what not, please contact Ian Johnston.
Section Four: Correlation
A. Introduction
One important job of statistics is the comparison between two different sets of information about apparently different things between which there may be a connection. For example, we might want to compare how information about people's income compares with the information about their education, in order to explore the claim that the more education one has, the greater the probability of a better income. Or, alternatively, we might wish to compare information about poverty with information about crime, to see if there is a possible link between the two, or, again, compare information about cigarette smoking habits with information about particular health problems (e.g., heart disease).
These sorts of studies involve comparing two variables (e.g., income and crime, smoking habits and health) in order to see if there might be some connection and perhaps even a suggestion of cause. As a cigarette smoking habit rises, do health problems also rise? As income decreases, does the frequency of crime increase? As people grow older to they become less or more tolerant of others?
What we are looking for in dealing with such questions statistically is what is called a correlation, an apparent connection between the different values in one set of data and in a second set of data, so that as the values in the first set increases, the values in the second set also tend to increase (or, in the case of a negative correlation, to decrease).
Here's a simple example. In an English course, once the instructor has marked a set of class essays, she has a record of the marks, one for each student. Then she assigns a second essay and marks it. Now, she has a record of the marks for two essays written by the same students.
The instructor might wish to know whether the students who did well in the first essay also tended to do quite well in the second essay, whether the students who did well in the first essay tended to do badly in the second essay, or whether there was no apparent connection between the results of the first essay and the results of the second essay (such information would be a useful test of the value of the first essay as a predictor of success in the second). In other words, she might like to see whether there is any significant correlation between the two sets of marks.
Common sense suggests to us that some sets of results should be quite closely correlated. For instance, we would expect the results students received in English 111 to be positively correlated to the results in English 112 (so that students who did well in the first should tend to do well in the second; students who fared poorly in the first course should tend to fare poorly in the second). Similarly, we would expect people who exercise regularly to have a healthier cardiovascular system than those who do not or those who are wealthy to spend more on consumer goods, and so on.
But in some cases our common sense expectations may be wrong, and often we may be interested, not just in whether there is a correlation or not, but in how strong that correlation might be.
B. Positive, Negative, and No Correlation
In considering correlation we recognize three distinct possibilities. The two sets of variables (that is, the two sets of data we are comparing, like exercise and cardiovascular health) may show a positive correlation. That is, as the values in the first set of data rise, the values in the second set of data tend to rise as well (i.e., those who exercise regularly have a greater cardiovascular health). Or the two sets of data may display a negative correlation. That is, those who score higher on the first set of results tend to get lower scores on the second set of results (e.g., the number of alcoholic drinks one has consumed and one's ability to carry out a manual dexterity test). Or, finally, there may be no correlation: the two sets of data do not appear to have any relationship.
Correlations, as we shall see, can be weak or strong, that is, the relationship between the two sets of values may be really significant or may be slight. A correlation can also be perfect, that is, every change in one set of values may show a exact corresponding change in the second set of values (the paragraphs below contain some examples).
Correlation is an extremely important analytical tool which enables us to begin to sort out claims about important connections, which may or may not be true: the amount of smoking and the incidence of lung cancer, HIV infection and the onset of AIDS, the age of a car and its value, television programming of playoff games and attendance at lectures, poverty and crime, IQ tests and income levels, intelligence and heredity, age and mechanical skills, and so on. People make claims about such matters all the time. The principle of correlation enables us to investigate such claims in order to understand whether they are true or not and, if true, just what the strength of that relationship might be.
In the following section we will work our way through a few examples, using Excel to do all the difficult work. At this point make sure you understand just what the concept of correlation (positive, negative, zero) means.
C. Self-Test on Correlation Terms
Indicate for each of the pairs of variables listed below what common sense tells you to expect in the way of an overall correlation between the two sets (positive, negative, perfect, zero):
1. height in centimetres and height in inches;
2. levels of income and amount of spending on consumer goods;
3. the age of a car and its value;
4. two scores thrown on two dice simultaneously;
5. snowstorms and attendance at college classes;
6. ability to see in the dark and the amount of carrots eaten;
7. daily cigarette consumption and cardiovascular health;
8. heights and weights of elementary school children;
9. weekly consumption of calories in food and drink and body weight;
10. age and physical strength in senior citizens.
D. Working with an Example
Suppose we wish to explore the claim that people's political participation increases with the number of years they spend in school. We think this claim is true, but we wish to substantiate it. In other words, we wish to see whether there is a correlation between the participation in the political process and years of formal education.
First, we collect data from each person in the study. We devise a test to measure a person's participation in the political process; we have people provide the appropriate information on this variable, and we ask them the tell us their years of formal schooling. This collection yields the following information:
| Respondent | Political Participation Score | Years of Formal Schooling | Respondent | Political Participation Score | Years of Formal Schooling | |||
| A | 1 | 5 | K | 7 | 13 | |||
| B | 2 | 8 | L | 8 | 14 | |||
| C | 2 | 7 | M | 8 | 15 | |||
| D | 3 | 9 | N | 9 | 15 | |||
| E | 3 | 10 | O | 7 | 13 | |||
| F | 4 | 11 | P | 10 | 16 | |||
| G | 5 | 11 | Q | 9 | 16 | |||
| H | 6 | 11 | R | 8 | 14 | |||
| I | 5 | 12 | S | 9 | 13 | |||
| J | 6 | 12 | T | 9 | 14 |
From a glance at the figures, we might conclude that there seems to be some relationship, for the higher scores in the middle column appear to be accompanied, in general, by higher scores in the right-hand column. However, we want to be sure about this point and not simply rely upon visual impressions from such a table.
E. Creating a Scatter Diagram in Excel
One standard way visually to express the correlation between two sets of variables is to draw a diagram in which each result is plotted on a standard X-Y graph. The X-Axis represents the value of one variable and the Y-Axis the value of the other variable. Each score in the set (in our example from Respondent A to Respondent T) is plotted on the graph, so that a distinct point is located for each member in the data set according to the two numerical values associated with each respondent.
For example, for the above data, we can construct a graph in which the value for the Years in School is plotted on the X-Axis and the value for Political Participation is plotted on the Y-Axis. Thus, we can locate each respondent's position exactly on the graph. We will come up with twenty points.
The following chart (created by Excel) illustrates the results. Notice that there are 20 points plotted and that each corresponds to a particular Respondent's scores in the two columns of the table above.
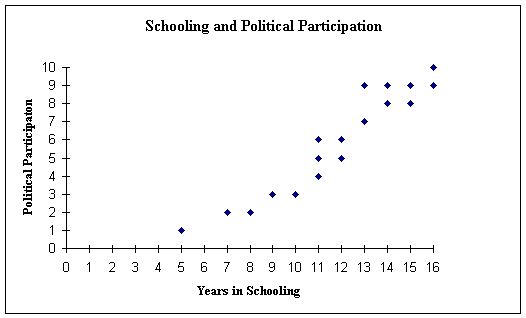
Notice that two people have 16 years of formal schooling (two values on the vertical line drawn through 16 on the X-Axis). Four respondents are shown on the graph with a Political Participation Score of 9, two with a Political Participation Score of 8, two with a Political Participation Score of 2, and so on. We call such an illustration a scatter diagram or scatter plot. Make sure you are familiar with what this graph represents and how to read it. Do not proceed until you feel very comfortable with this visual presentation of information.
Look for a moment at the overall shape of all the points in the chart. It seems to be characterized by a generally linear cluster which rises upward and to the right. This shape suggests strongly that as the Y values rise (i.e., go vertically upward), the X values increase also (i.e., move to the right). This point is not true for every single point in the cluster, of course, but as an observation about the overall general shape of all the points, that claim seems to hold. Thus, these results seem to show a positive correlation: the higher the value for the years of formal schooling, the higher the score on the Political Participation test—that seems to be the general trend of the entire range of respondents (even if some of the plotted points do not follow that overall trend).
F. The Line of Best Fit (Regression Line)
One way to emphasize the overall orientation of all the plotted points in the scatter diagram is to draw through the plotted data a straight line which comes as close as possible to all of the plotted points. Such a line is called the line of best fit (or the regression line). If we do that for the above graph (and Excel will draw such a line for us), we can recognize immediately the overall orientation of the results as sloping upward and to the right.
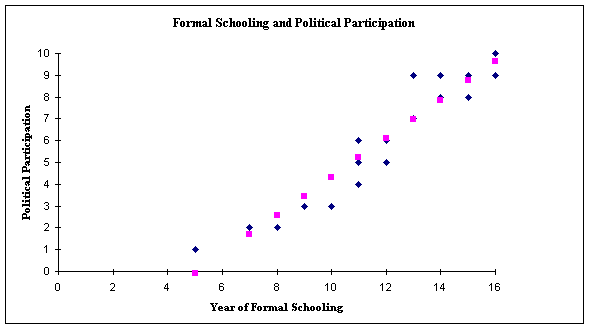
Notice that this chart presents the same data as the last chart, except that there is a plotted straight line (of square points) through the points plotted from the data we collected from the respondents (the diamond shaped points). This line, which is derived from the plotted points, is the straight line which comes closest to all the points which correspond to the measured data. It is called the line of best fit or the regression line.
We can see from this line of best fit that it very clearly slopes upward and to the right. This confirms our sense from the overall shape of the cluster that it indicates a positive correlation: an upward slope clearly demonstrates that as the Y values increase the X values tend to increase.
We can use the regression line, once we have drawn it, as a general predictor. That is, with the line in place, we can use it to read off values for cases not included in the study. For example, if we want to know what this data reveals about the probable political participation score someone with 14 years of formal schooling, we can read directly up from the value 14 on the X-axis, see where it meets the regression line, and read horizontally across to the Y-axis. That value in this chart is (about) 7.8. Thus, on the basis of this study, we can offer a prediction that someone with 14 years of formal schooling will probably have about 7.8 as a political participation score. Obviously, this is not a sure-fire guarantee of such a score; it is, however, something of an educated guess.
Using the regression line in this manner obviously yields only approximate results, and it may in some cases be misleading if we rely on it too heavily (you notice, for example, that most of the plotted points, which represent the hard data, the actual people in the study, do not fall directly on the line). It is, at best, a rough guide in a study of the sort we have been considering.
A Common Misuse of the Regression Line
It is often very misleading to use the regression line to make predictions outside the range of the data. For instance, I can extrapolate (extend) the straight line, once I have drawn it, and then make predictions well beyond the plotted points (say, about the political participation of someone with 21 years of schooling). This is often an illegitimate procedure leading to very wrong conclusions (as we shall see from a couple of examples).
We can draw in a Regression Line by hand, visually estimating where it should come. This is obviously a somewhat subjective procedure, and different people drawing the line will come with slightly different results. Excel, however, will plot the line for us very quickly (as it did for the above diagram). We will be reviewing that procedure later.
Please remember always that a positive correlation does not mean that there will no exceptions to the overall trend. There may be one or more results which do not fit the overall trend of the entire collection of data. Correlation deals with the general tendency of the entire collection of data.
G. An Example of a Perfect Correlation
Here is another set of measurements. This time the middle column represents the student's scores in percentages for class participation, and the column on the right represents the same score out of 20.
Name of Student |
Participation Mark (100) | Participation Mark (20) | Name of Student | Participation Mark (100) | Participation Mark (20) | |||
| ab | 65 | 13 | hi | 72 | 14.4 | |||
| bc | 90 | 18 | ij | 82 | 16.4 | |||
| cd | 83 | 16.6 | jk | 94 | 18.8 | |||
| de | 74 | 14.8 | kl | 50 | 10 | |||
| ef | 84 | 16.8 | lm | 75 | 15 | |||
| fg | 78 | 15.6 | mn | 58 | 11.6 | |||
| gh | 60 | 12 |
If we plot these points on a scatter diagram as before, putting the Participation Mark (100) on the X-axis and the Participation Mark (25) on the Y-axis, then we get the following diagram:
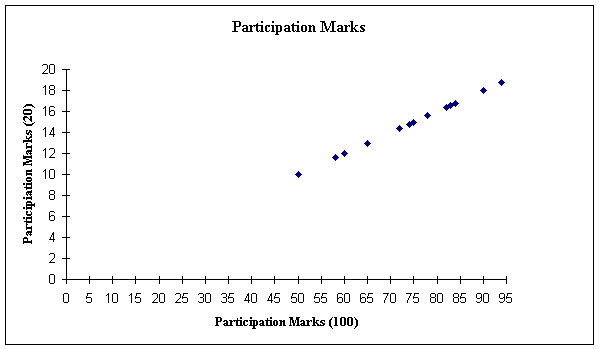
Notice here that the general shape of the plotted points moves upward and to the right—indicating once more a positive correlation. In this example, there is an added observation: the data we plotted forms a perfect straight line, with every plotted point from the data we collected falling exactly on the same straight line. Clearly, if we wanted to draw a line of best fit here, it would coincide exactly with all the data. Such a result produces what we call a perfect positive correlation: every increase in the value of the X-axis brings about an exactly corresponding increase in the Y-axis value. We would expect this result, of course, because the values are basically the same measurement. A similar result would occur if, for example, we plotted the weight of ten students in grams against the weight of the same students in pounds or a range of temperature readings in Celsius against the same readings in Fahrenheit.
Here is another pair of sets of variables. The first indicates the distance traveled in a new prototype car through the desert at an even speed. The second column indicates the amount of gasoline left in the car's gas tank at each of the inspection points.
| Place | Distance from Home (Miles) | Gasoline Left in the Tank (Gallons) | Place | Distance from Home | Gasoline Left in the Tank (Gallons) | |||
| Home | 0 | 15 | Deadman | 425 | 6.5 | |||
| Podunk | 50 | 14 | No Mo Gas | 540 | 4.2 | |||
| Buzzard Breath | 150 | 12 | Last Chance | 680 | 1.4 | |||
| Paradise | 275 | 9.5 | Hope Gone | 700 | 1 | |||
| Last Hope | 350 | 8 | Nowhere Town | 750 | 0 |
Once again we can illustrate these values in a scatter plot diagram to observe the nature of the correlation:
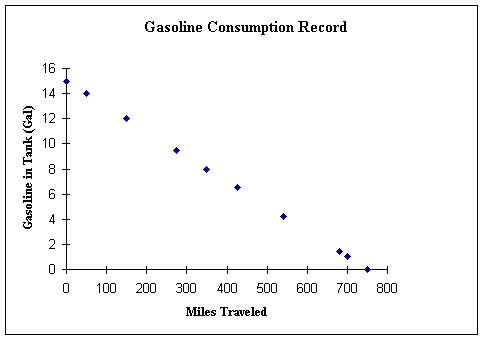
Here we see again that we are dealing with a perfect correlation, because all the plotted points fall on the same straight line. But this time the line slopes downward and to the right. This indicates that the highest values on the Y Axis are associated with the lowest values on the X-Axis, or that as one value increases the other decreases (as the distance increases the gasoline left in the tank decreases). This example illustrates a perfect negative correlation.
Just as in the first example (about political participation scores) we can have a positive correlation which is not exact, so we can find a negative correlation which is not exact. In such a case the plotted points will not all fall on the same straight line, but the general shape of the cluster (and the regression line we draw through them) will slope downward and to the right.
For example, if we plotted a set of figures indicating the amount of alcohol consumed against a second set of figures indicating success in a simple test of physical dexterity, we would expect to get a negative correlation: the more drinks consumed, the lower the score in the physical dexterity test. Here is an example of such a scatter plot.

The shape of this data in the scatter diagram indicates what we would expect, a negative correlation. As the values on the X-Axis (the number of drinks) increases, the value on the Y-Axis (the physical dexterity score) decreases
H. Zero Correlation
When there is no correlation at all between the two sets of variables, then we will have trouble recognizing an upward or downward overall shape to the plotted data, and the line of best fit will fall somewhere in a horizontal position among the plotted points.
For example, here are two sets of variables: the first lists the number of letters in the name of geographical location in Canada, and the second lists its longitude (approximately). We want to know if there is a correlation between how many letters there are in a Canadian place name and its geographical location. Our common sense suggests that there should not be a correlation, but we just want to check
| Name | Number of Letters in the Name | Longitude | Name | Number of Letters in the Name | Longitude | |||
| Prince Rupert | 12 | 130 | Biggar | 6 | 108 | |||
| Courtenay | 9 | 125 | Pickle Crow | 10 | 90 | |||
| Kirkland Lake | 12 | 80 | Williams Lake | 12 | 122 | |||
| Brandon | 7 | 100 | Yarmouth | 8 | 66 | |||
| Glace Bay | 8 | 60 | Sherbrooke | 10 | 72 | |||
| Clarenville | 11 | 54 | Oba | 3 | 84 | |||
| Dundas | 6 | 80 | Calgary | 7 | 114 | |||
| Lac Ste Jean | 10 | 72 |
If we plot these points on an X-Y graph to produce a scatter diagram, we can then inspect the distribution and draw in a line of best fit. The plotted data looks as follows:
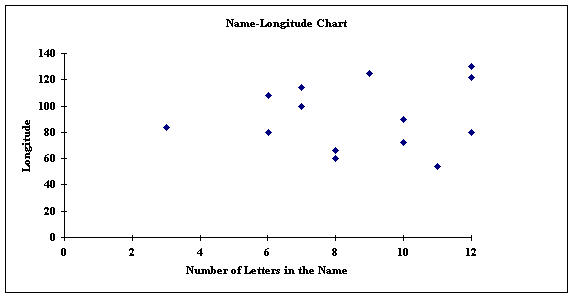
Try to estimate where you would draw the regression line through these plotted points. Notice that one cannot so easily produce one like those we have already drawn, that is, with a distinct slope indicating a positive or negative correlation. And, thus, based on the very small sample we chose, from a visual inspection of the plots, there does not seem to any relationship between the number of letters in a Canadian place name and its approximate longitude.
.I. Mathematical Measure of Correlation: The Correlation Coefficient (r)
The scatter plot diagrams and the regression line give us a general visual idea of what the correlation is between two sets of variables. In many cases, however, we require a more accurate measure, so that we can compare one correlation with another. In other words, knowing that a correlation exists is valuable; more valuable, however, is to know the size of that correlation. Such a mathematical measure of the correlation between two sets of variables is called the Correlation Coefficient. It is most commonly symbolized by the letter r.
The following paragraph outlines how the Correlation Coefficient is calculated. However, this method is something Excel will do for us, once the data is entered. The method is listed here for interest:
1. First we transform the scores in each of the sets of data into z-scores. Remember that a z-score is a measure of how far any particular score is from the mean of the entire set and that the units of z-scores are standard deviations (i.e., a z-score of 2.5 means that this particular value is 2.5 standard deviations above the mean; a z-score of -1.8 means that this value falls 1.8 standard deviations below the mean)
2. We then multiply together the corresponding z-scores in each list (i.e., the z-score for one measurement is multiplied by the z-score for the corresponding measurement from the other set of data. Remember that a positive number multiplied by a negative number produces a negative result; a negative number multiplied by a negative number produces a positive result.
3.Then, we add up all the results produced by Step 2 above.
4. Finally, we divide the figure obtained in Step 3 by the total number of pairs of scores (i.e., get the average of figures derived in Step 2.This process will always produce a number between -1.00 and +1.00. This number is called the correlation coefficient (symbolized by the letter r). If r = -1, then the correlation is a perfect negative correlation; if r = 1, then the correlation is a perfect positive correlation. If r = 0, then the correlation is zero (no relationship between the variables).
J. Exercise in Calculating the Correlation Coefficient with Excel
Here's an exercise to demonstrate a practical application of correlation and to show how Excel will do all the mathematics for us.
Suppose, as teachers or employers, we are interested in whether a particular diagnostic test we have been using is a good predictor of success. In other words, does the mark on an entry-level test give us reliable information about how well a particular person will do in, say, an academic program? One way of answering this question is to use correlation.
Here is a chart of data we collected on ten subjects (not a large enough sample, but it will enable us to go through the procedures for calculating correlation). Each one wrote the same diagnostic examination to get into a course, and each one wrote the same final examination eight months later.
| Name | Diagnostic Score | Final Mark (100) |
Name | Diagnostic Mark | Final Mark (100) | |||
| ab | 76 | 80 | fg | 64 | 70 | |||
| bc | 85 | 76 | gh | 85 | 83 | |||
| cd | 86 | 62 | hi | 89 | 84 | |||
| de | 75 | 84 | ij | 71 | 70 | |||
| ef | 84 | 87 | jk | 87 | 80 |
Enter this data onto a new Excel worksheet, putting the results of the diagnostic test in Column A (from A1 to A10) and the results on the Final Mark in Column B (from B1 to B10). To get Excel to conduct a correlation analysis on the data, carry out the following steps.
1. First, point and click on the Tools option on the top line, and from the drop-down menu select Data Analysis, which is normally the last item on the menu. Note that if Data Analysis does not appear you will have to add that to the Tools option (using the process explained in a previous section, in Part J). When the Data Analysis menu appears left click the mouse on the option Correlation.
2. You will then get a box asking you for the Input range and the Output range. The Input range is the group of cells you want in the analysis (in this example the ten cells in Column A and the ten cells in Column B). Enter this information in the Input Range box, not forgetting the dollar signs which indicate a range: $A$1:$B$10; this command is telling Excel to include in the analysis the rectangular block of cells defined by A1 and B10 at the corners. You do not have to enter the range manually (by typing in the figures), if you click the left mouse button with the cursor in the Input Range box and then select the entire table of data, the range figures ($A$1:$B$10) will appear. If you have put the names in column A and the headings in row 1, do not select them for analysis. Select only the numbers.
3. Then, click the left mouse button in the circle to the left of the label Output Range (unless there is a dark dot in the circle already to indicate that that option has been selected). Then click the left mouse pointer in the Output Range box (the long horizontal blank rectangle). Once you have clicked the mouse button in that box, enter the name of the cell where you want the data to appear (once again the top left corner of the table you are about to generate). Let's choose cell D1. So in the Output Range box type in $D$1. Then click on OK. Once again, you do not have to type that in the Output Range box, if you click the left mouse button with the cursor in the Output Range box and then select cell D1.
4. After a moment, on the worksheet a small table will appear with its top left hand corner in Cell D1. This table indicates the correlation between the columns. In the case of our example, the correlation between Column 1 (Diagnostic Score) and Column 2 (Final Mark) is 0.31 (or r = 0.31). Thus, in this case the mathematical calculation carried out by Excel reveals a small positive correlation between the results on our diagnostic test and the results on the final mark.
Notice in the small table we generated in this exercise that the correlation of Column 1 and Column 1 is 1 (i.e., perfect), as we would expect, since we are comparing that column with itself. The same is true for the correlation between Column 2 and Column 2.
K. The Strength and Significance of a Correlation Coefficient
Now that we have a mathematical value for our correlation coefficient (r = 0.31), how are we to interpret that? Does this mean that our diagnostic test is a good one, that we can rely on it?
As mentioned earlier, the strongest positive correlation is 1.0, and the closer our r value is to 1.0 the stronger the correlation between the two sets of values we are analyzing. The closer to 0 our r value, the weaker the correlation. The following general categories indicate a quick way of interpreting our calculated r value:
0.0 to 0.2 Very weak to negligible correlation
0.2 to 0.4 Weak, low correlation (not very significant)
0.4 to 0.7 Moderate correlation
0.7 to 0.9 Strong, high correlation
0.9 to 1.0 Very strong correlation
Our result of 0.31 is thus very weak or low; as an evaluative tool our diagnostic test is not all that useful, since the results on it do not reveal very much about the future results in the final marks. There is some positive correlation, but not enough to make the diagnostic reliable as a predictor (say, for counseling students or alerting the teacher to potential problem students).
One useful rule of thumb for estimating the importance of the r value is to calculate the square the correlation coefficient (i.e., calculate r2). This squared result will give us a rough percentage for the amount of variation in the final result which is directly attributable to the other variable.
For example, suppose our diagnostic test was a good measure of writing ability. The correlation between that writing test and the final marks is 0.31. If we square this value, we get the value 0.096, or 96 in 1000 or 9.6 percent. On the basis of this, we can claim that 9.6 percent of the students' success in the course is attributable to the writing skills they had at the very start of it (i.e., what we measured in the our diagnostic test). We would then have to conclude that success is this course is not very dependent upon the writing skills the students have upon entry.
Suppose now we administer another diagnostic test at the very start of the course, this time measuring reading ability. And we discover when the course is over that the correlation between the results of that diagnostic test and the final marks for the course is 0.8 (r = 0.8). If we square 0.8, we get 0.64 or 64 percent. We can then claim that 64 percent of the students' success in the course is directly attributable to the reading skills they possessed (and which we measured) when they started. Obviously, this conclusion assumes that the diagnostic test is an excellent measure of the students' reading ability.
It will be apparent that correlation analysis is a very useful tool for investigating all sorts of claims. We may often think that one particular skill, quality, or value has a direct and important effect upon another (i.e., years in school and income at age forty, frequency of smoking and incidence of heart disease, success in a particular test and success in something different, and so on). Correlation analysis enables us to test such claims and to provide some quantifiable measure to them.
L. Some More Examples
Here is another common example of the usefulness of correlation. Suppose we are interested in dealing with a question of heredity: Is there a relationship between the height of mothers and the heights of their sons and, if so, how strong is it? Well, we carry out a series of measurements of the heights of mothers and sons and conduct a correlation analysis of the results. Suppose we discover that the correlation coefficient in our study is 0.7 (i.e., r = 0.7). If we square this figure, we get 0.49, or 49 percent.
This means that 49 percent of the variation in the sons' heights can be attributed to the heights of their mothers. This correlation is moderate and indicates that predicting the height of a son on the basis of his mother's height is moderately successful. The remaining 51 percent of the factors influencing the sons' height come from elsewhere (e.g., the fathers, environment, food, and so on).
Suppose further that we now conduct a correlation study with the same sons, but this time analyzing the relationship between their heights and their fathers' heights. We find that r = 0.8. If we square this we get 0.64. We can thus estimate that 64 percent of the sons' variation in height is attributable to their fathers' heights.
You might be drawn into some confusion here: if 64 percent of the sons' heights is attributable to the fathers' height and 49 percent to the mothers' heights, then we have more than 100 percent. How can that be? Well, in some cases the heights of the mother and the father act together in determining the height of the child. Statistically speaking, the heights of the fathers and the heights of the mothers are also correlated, since people tend to marry people closer to their own height—or taller women tend to marry taller men and vice versa, and shorter women tend to marry shorter men, and vice versa. So the total effect is more complex than just adding together the two separate percentage contributions.
M. Self-Test on Excel's Correlation Function
We want to track the progress of a class of ten students in a particular class of English 111, in order to ascertain if our ways of predicting success in the course are useful. We have a record of their Grade XII marks, and we administer a diagnostic reading test in the first class. At the end of the semester, we have the final marks of the students. We now wish to know which of the two assessments—the Grade XII mark or the Reading Test Mark—provides a better guide to the students' success in the English 111 class. We will assume for the sake of this exercise that the sample is an accurate one (even though it is too small)
.Here is the raw data, presented in tabular form. Copy this information onto a fresh Excel worksheet, putting the names in Column A, the Grade XII results in Column B, the Diagnostic Test Marks in Column C, and the Final Marks in Column D.
| Name | Grade XII Mark (100) | Diagnostic Reading Test Mark (100) | Final Mark (100) | ||
| ab | 75 | 75 | 75 | ||
| bc | 72 | 69 | 76 | ||
| cd | 82 | 76 | 83 | ||
| de | 78 | 77 | 65 | ||
| ef | 86 | 79 | 85 | ||
| fg | 76 | 65 | 79 | ||
| gh | 86 | 82 | 65 | ||
| hi | 89 | 78 | 75 | ||
| ij | 83 | 70 | 80 | ||
| jk | 65 | 71 | 70 |
When you have entered the information, select the three numbered columns (do not include any cells with words in them). Go to the Data Analysis option on the Tools menu, select from that Data Analysis menu the item Correlation (note, once again, that if the Data Analysis option is not on the Tools menu you have to add it in).
When you get the Correlation menu, enter in the Input Range the block of cells you wish to analyze (i.e., from B2 to D11, if you have used Column A for the names and Row 1 for the titles). Do not forget to put in the dollar signs.
Then click the mouse pointer in the circle to the left of the Output Range label (unless there is a black dot in it already), and click the left mouse button in the Output Range box. Then enter the name of cell where you want the top left corner of the correlation table to appear (e.g., $A$13). Then click OK.
After a second or two, the Correlation Table should appear giving you the correlation between all the different pairs of data. We are interested in the correlation between Column B (the first column in the Table) and Column D (the third column in the table) and between Column C (the second column in the Table) and Column D. Which of these two is the better predictor of success according to this study. How reliable is it? For the answers see the paragraphs at the end of this section.
Using this procedure we can examine the correlations between several sets of data entered on an Excel worksheet. For example, if we have all the marks for all the Liberal Studies assignments entered on a single sheet, together with the final mark, we can simultaneously calculate the correlation between the marks for any particular set of assignments and the final result. This would, among other things, enable us to estimate which assignments were the best and worst predictors of success in the program.
N. A Strong Caution
It is very important to grasp the point that a correlation, even a very strong correlation, does not enable us immediately to make a conclusion about causation. If, for example, we find a very high correlation between the number of years people spend in post-secondary education and their income at age 40, we may make some predictions about income at age 40 based on years of post-secondary education or we may urge people to stay in university because the more they study at university the higher their eventual income will tend to be, but we should be aware that the correlation, in itself, is no proof of these assertions.
This is a vitally important principle: correlation is not necessarily a proof of causation. It indicates a relationship which may be based on cause and effect, but it may not be. If A is a major cause of B, then we can expect that variations in A will cause changes in B (i.e., there will be a correlation). The reverse, however is not necessarily true. If X and Y are correlated, we cannot automatically assume that X is the cause of Y.
This issue is an important point of contention in the political disputes about AIDS. There is a very high correlation between HIV infection and the occurrence of AIDS, and thus many researchers have from the start assumed that HIV is the principal cause of AIDS. On the basis of this assumption, most of the research money for AIDS has gone into investigating HIV. Yet it is still not clear what causes AIDS, and some people (especially those suffering from AIDS) have argued very strongly that investigating HIV instead of AIDS is a mistake: the real cause is something else, something which requires much more money going directly into research on AIDS rather than into HIV. The social, political, medical, and financial consequences of this argument are substantial.
Suppose we do find a significant positive correlation between two variables, X and Y (for example between provincial government expenditures on education and the average income of citizens), we recognize that there may be four different reasons why this relationship exists:
1. First, X may indeed cause Y. That is, the fact that the provincial government spends more on education is indeed the reason that more citizens stay in university longer and get higher paying jobs when they graduate. Thus, the average income of the province increases.
2. Secondly, however, the result may be just chance. This is quite possible if we are sloppy about our sampling (we haven't talked about that). But if we make many observations and sample the population correctly and repeatedly, this reason for the correlation becomes very unlikely (the more the tests the less likely that the results occur by chance).
3. Thirdly, there may be some third factor we have not taken into account which produces the variation in both X and Y and which is the real cause of the correlation. This conclusion seems to be emerging in the analysis of AIDS and HIV (1).
4. Finally, there may be a causal connection which is responsible for the correlation, but we may have put it the wrong way around. We might conclude from the high correlation between the government's expenditures on post-secondary education and average family income that the expenditures on education are causing that increase in income. But it may be the case the higher family incomes are caused by something else; they are providing the government with increased tax revenue, which the province (for any number of reasons) has decided to spend on post-secondary education (thus making education more accessible and affordable and, hence, more popular).
Does this ambiguity in interpretation mean, then, that correlation studies are of limited value? By no means. It simply reminds us that we have to be careful about the conclusions we draw from a correlation study. Remember this important point: every time a particular factor (A) is a cause of something else (B) there will be a correlation between them. Thus, we can use correlation as a negative test. If there is no correlation between two variables, we can assume that one of them is not a cause of the other. If there is a correlation we have strong evidence that one of them may be the cause of the other and that we should, therefore, investigate further.
O. Self-Test on Correlation Charting and Calculations
Here are the numerical results of a hypothetical study in which various skills measured independently are to be analyzed for a possible correlation with annual earnings among a group of salesmen in similar industries. Enter these figures onto an Excel worksheet, and generate a correlation table for all the data. Which of the four measured qualities has the strongest positive correlation with the annual salary?
| Name of Salesman |
Public Speaking | Writing Ability | Math Skills | General Knowledge | Annual Earnings | ||
| ab | 76 | 64 | 53 | 77 | 80,000 | ||
| bc | 56 | 64 | 89 | 75 | 60,000 | ||
| cd | 77 | 70 | 60 | 70 | 72,000 | ||
| de | 90 | 95 | 62 | 82 | 92,000 | ||
| ef | 68 | 68 | 88 | 68 | 65,000 | ||
| fg | 83 | 85 | 61 | 85 | 90,000 | ||
| gh | 61 | 60 | 79 | 85 | 54,000 | ||
| hi | 79 | 73 | 82 | 68 | 80,000 | ||
| ij | 64 | 83 | 59 | 81 | 65,000 | ||
| jk | 88 | 62 | 89 | 66 | 79,000 |
When you have discovered the quality which appears to have the strongest correlation, produce a scatter plot diagram to illustrate the relationship between this quality and the annual salary (you will be dealing with only two columns of data: the figures for the column representing the highest correlation and the annual earnings).
If you wish to produce a scatter plot with a regression line, then follow the procedure given below:
1. Select Tools and then Data Analysis. And from the options select Regression. In the Input Y Range Box, enter the range for one column of scores. In the Input X Range, enter the range for the other set of scores.
2. Click the circle to the left of the label Output Range (so that there is a black dot in it), then enter into the Output Range box, the cell where you want the top left corner of the data to appear.
3. Make sure you then you select Line Fit Plots by moving the cursor to the square box beside the label and clicking the left mouse button once. There should now be a check mark in that box. Then click OK.
4. Now a very complex looking table will appear. If you move to the right of the worksheet, you will see a small chart. Select the chart and enlarge it. You will notice that the chart is a scatter plot diagram with a regression line plotted through the points (similar to the diagram in Section F above).
P. Transferring an Excel Diagram to Another Windows Application
When you have created a chart in Excel, you can, as mentioned above, print the chart directly from Excel. However, in many cases you may want to transfer the chart into WordPerfect or Word document, so that the illustration appears in the middle of your own text (as in this module).
This procedure is fairly easy to do, so long as both Excel and the word processing program are in Windows. Here is an outline of the simplest procedure.
Create or call up the chart in Excel. Make sure the chart has all the shadings and headings and borders and legends you want. Once the chart has been formatted to your satisfaction, select the entire chart by the method outlined earlier (so that the outer perimeter of the chart is demarcated by small squares). You can alter elements of the chart once it is in your word processing document, but the options are more limited and sometimes more difficult to carry out than in Excel. So make sure the chart looks just as you want it to in the word processing document before you transfer it.
Important Warning
Before you start trying to move material (e.g., charts) from one document to another, make sure you save the Excel worksheet which contains the chart. It is not uncommon for mistakes to occur the first couple of attempts, and you will save yourself considerable time if you can go back to the original Excel chart and start the transfer again, rather than having to generate the chart all over again.
Then, with the chart selected, point the mouse arrow onto the Edit option at the top of the screen, click the left mouse button, and from the drop-down menu select Copy. Once you do that, you will notice that the chart now has a flashing dotted line around it (indicating that it has been selected for copying).
Now, place the mouse arrow directly on the button with a negative (minus) sign in the very top left of your Excel window (just above and to the left of the word File). From the drop-down menu, select Minimize. Your Excel document will then disappear, and a small Excel icon will appear on the bottom left of your screen, with the name of the Excel file containing the chart under the icon. Whenever you want to return to the Excel chart, all you have to do is click the mouse on this Excel icon.
Now call up the word processing program you want from the Windows Applications menu. Once in the right program, call up the document in which you wish to place the chart, and move through the document until you have the exact place where you wish the chart to appear. Place the cursor in the exact place.
Then from the main menu at the top, select Edit, and from the drop-down menu select Paste. The chart should now appear, with the upper left hand corner in the spot where you placed the cursor. Note that if you have asked for the chart to be placed on a page where there is insufficient room for it, the Paste command will place the diagram on the next page (i.e., the diagram will not go over a page break).
Sometimes in the transfer from Excel to the word processing program, minor formatting problems may arise. Inspect the chart carefully once you have transferred it. If everything is as it should be, fine; if not, then you may need to edit the chart further in the word processing program. To put the diagram into the edit mode, double click the left mouse button with the mouse pointer on the diagram. In the edit mode you can make adjustments to the chart.
For instance, a common occurrence when you move an Excel diagram into Word is that the units of the X-axis become aligned incorrectly. You can deal with this in the Word diagram edit mode by selecting each figure on the X-axis and moving it back to the position you want it. To move a number, simply point to it with the mouse, hold the left button down. The number will change to a dotted rectangle which (with the left mouse button still held down) you can move up or down, to the left or to the right, as you wish.
In the same way, you can alter the text in the diagram once it is in your word processing document. When the diagram is suitable and you wish to exit from the edit mode, return to the normal document via the file menu on the diagram edit program (not the main file menu at the very top).
Note that in your text you can alter the size and the position of your chart. If you point the mouse indicator onto the diagram and click once, you will see that the chart has a perimeter line with some squares half way along each side. If you position the mouse indicator on one of those squares, the indicator will turn into a double arrow; press down the left mouse button and drag the side of the chart in the direction to want (to enlarge or reduce its size)
To centre the chart on the page, select the diagram, and choose the centre command, either from the Format-Paragraph option or from the centre button on the toolbar.
To move the chart to another place in the document, select the entire chart and then use the cut and paste function.
Q. Answers to Self-Test Questions
Self-Test On Excel's Correlation Function (Section M)
The correlation between the Grade XII Mark and the Final Mark is 0.23; the correlation between the Diagnostic Reading Test and the Final Mark is -0.28. Thus, the Diagnostic Reading Test has a negative correlation; the Grade XII Mark a positive correlation with the Final Mark, the negative correlation being slightly stronger than the positive correlation. However, both figures are so low, that the correlation is minimal. The skills measured by the Grade XII marks account for about 5 percent of the skills measured by the Final Mark.
Self-Test on Correlation Charting and Calculations
The correlation between the first column (Public Speaking) and Annual Earnings is 0.91, an extremely high reading. The scatter plot and regression line for these two variables looks something like the following:

Notes to Section Four
(1) This point was the subject of a very famous and controversial study of education and income carried out by Christopher Jencks. He analyzed the common claim that income at age 40 is directly correlated to the number of years of schooling (a very strong case for staying in school). Jencks argued that that correlation was, in fact, produced by a much more important factor, namely, the income of one's parents. People whose parents had more money tended to stay in school longer and tended to have higher incomes at age 40. Jencks concluded that the common claim about staying in school increasing one's earning power (i.e., causing an increase in income) was unsubstantiated. The real cause was parents' income. Not surprisingly, the book (Inequality) was very hotly debated. [Back to Text]
[Back to johnstonia Home Page]
Page loads on johnstonia web files
View
Stats