Vector vs. Raster
Vector
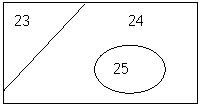
The vector – database structure of data is quite analogous to paper maps and tables of descriptive information. Consider the following:
|
ID |
Area |
Pop’n |
Rating |
|
23 |
10 |
4 |
Low |
|
24 |
55 |
15 |
Low |
|
25 |
8 |
85 |
Good |
|
Etc. |
|
|
|
The map has 3 polygons (distinct areas): 23, 24 and 25. The database has attribute information for each of these areas (each row is known as a record). In the database is a unique field (column of information), in this case “ÍD”. The map and the table share a piece of information – the unique identifier (much like each of us has a unique driver’s license number or social insurance number). We can now answer some simple questions, like:
1. Which is the largest polygon? (it is #24 at 55 hectares)
2. Which polygons have a “Low” rating? (#’s 23 and 24)
3. What is the population of polygon 25? (pop’n = 85)
These questions (and answers) demonstrate the power of linking map and attribute data. The example has only 3 polygons. Imagine answering question 2 if you had several thousand polygons in your map.
Other factors to note:
1. Map is made of line work (lines can be very accurate and nice for output)
2. Database could be quite comprehensive (thus a considerable amount of data can be “attached” to a map)
3. This is a very efficient way to store data (little disk space is required)
4. Vector is good for network analysis (i.e. emergency routing)
5. If the spatial data has discrete, “hard” boundaries, then vector lines will capture this change very well.
Raster
For vector there were two components: the map and a table of descriptive information. In the raster world the descriptive information is embedded in the map itself. Instead of using lines to define area (rather like an Etch-a-Sketch toy), numbers are placed inside of a grid of cells (similar to a picture made by a Lite Brite toy). Each cell can contain only one number. Thus if we wanted to have the same information as the previous example we would need a raster layer for each field of information (i.e. one layer for “area”, a second for “population” and a third for “rating”); see below. Note that the Rating layer has 1’s (for low) and 3’s (for high) as only numbers can go into pixels.
Area layer
|
10 |
10 |
10 |
55 |
55 |
55 |
55 |
55 |
|
10 |
10 |
55 |
55 |
55 |
55 |
55 |
55 |
|
10 |
55 |
55 |
55 |
8 |
8 |
8 |
55 |
|
10 |
55 |
55 |
55 |
8 |
8 |
8 |
55 |
|
55 |
55 |
55 |
55 |
55 |
55 |
55 |
55 |
Population layer
|
4 |
4 |
4 |
15 |
15 |
15 |
15 |
15 |
|
4 |
4 |
15 |
15 |
15 |
15 |
15 |
15 |
|
4 |
15 |
15 |
15 |
85 |
85 |
85 |
15 |
|
4 |
15 |
15 |
15 |
85 |
85 |
85 |
15 |
|
15 |
15 |
15 |
15 |
15 |
15 |
15 |
15 |
Rating layer
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
1 |
1 |
1 |
1 |
3 |
3 |
3 |
1 |
|
1 |
1 |
1 |
1 |
3 |
3 |
3 |
1 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
The grid is fixed. For each new category of information we need a new layer. Because the structure is fixed:
1. Overlays are straight forward (lay one grid over another and the pixels all line up)
2. Data that varies continuously over space (elevations, temperature, sound level from an airport, etc.) is readily captured in the grid.
3. Satellite information already comes in grid format and is easily incorporated and manipulated in a raster system.
4. As each field of information requires its own layer, more storage space is required.
Examples of vector and raster data sets
Vector: If features (points, lines and polygons with definite boundaries) are discrete, then mapping with vector line work is most appropriate. Also, if these features have a lot of information to go along with them, then a database is the place to store the data. Examples include:
1. Sample sites at point locations (population of various fungi noted at a sample plot, water contaminants in wells)
2. Stream (or road) networks where the network is broken down into segments (i.e. stream reaches where depth, width, substrate, slope%, etc. are fairly constant)
3. Area theme where boundaries are fairly distinct; this is usually in the form of an “inventory” (i.e. forest cover, habitat types).
With each of these types a database with many fields can be associated with it.
Raster: If there are no distinct boundaries and the variable of interest changes continuously over the landscape then raster is best. Examples include elevation, slope, aspect, concentrations of contaminants, population densities, etc.
Vector & Raster Combined: In many instances both data formats are required. Take point samples of pollution. Data is collected at points. However, the pollution is obviously not restricted to those points, it exists across the landscape at varying levels. Sampling at points was simply an expedient way of collecting data (similar to obtaining spot heights from survey information). A surface of pollution levels (i.e. a raster grid) can be generated from the point data. After the raster grid has been created many analyses can be conducted in raster (i.e. derive change in pollution (slope) and “direction of change” (aspect) of pollution, correlate pollution levels to land use (a second theme)). In addition to a surface, a “contour” (isoline) map can be created. If pollution data had been collected over a period of time, then two pollution grids could be created (one for each time period) and the two images could be compared to determine change over time.