- Basic Statistics
- Terms of Endearment
- pop'n vs. sample
- parameter (true value of pop'n) vs. statistic (estimate from sample)
- sample size = n
- "centre": mean
- "variability": range, standard deviation, coefficient of variation
- frequency distributions of data (e.g. grades)
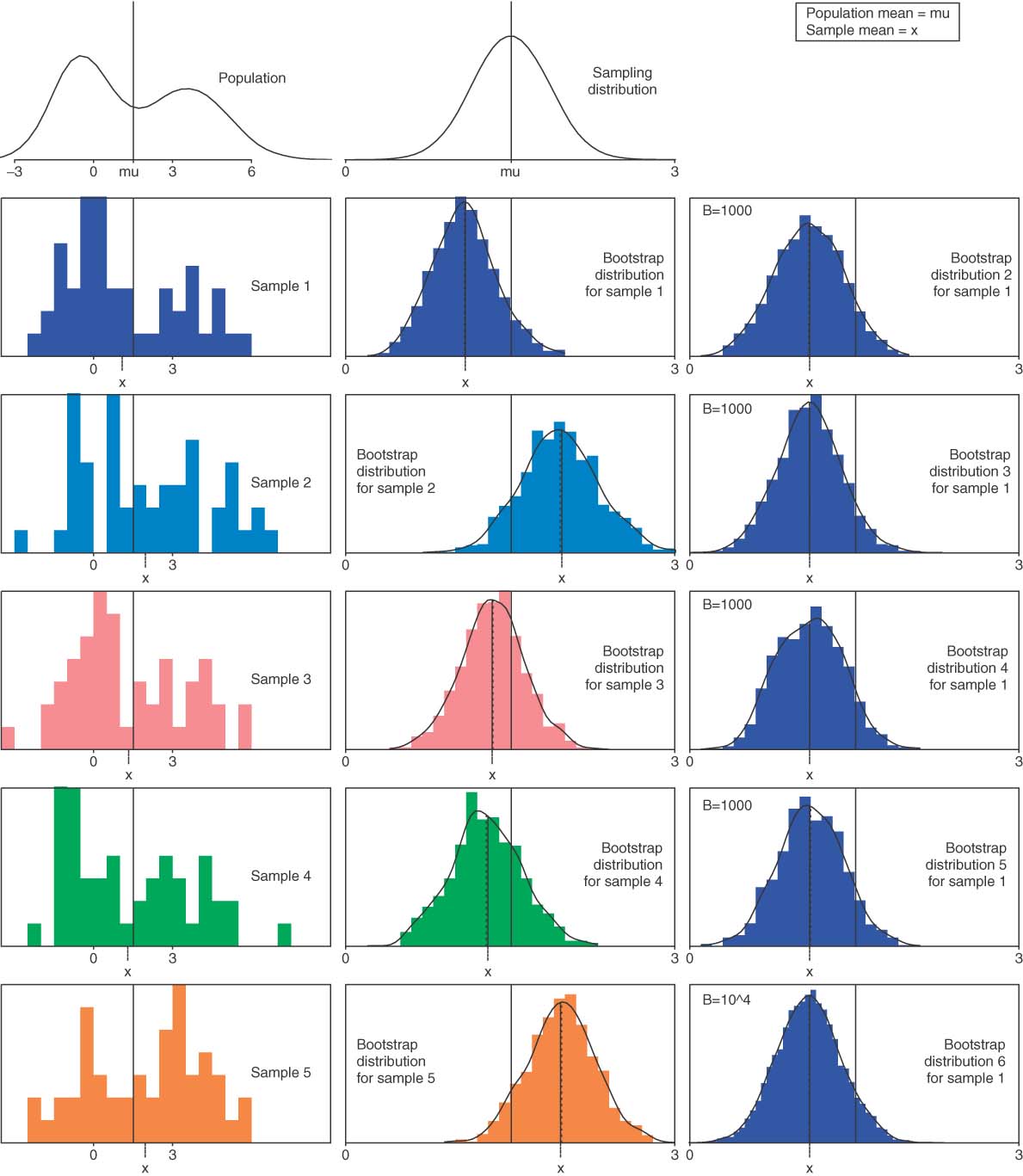
- What's Normal Anyways?
-
- bell shaped
- centred on mean
- symmetrical
- inflection point = 1 "SD"
- +- 1SE = 68.3%, ... 95.4%, ... 99.7%
- what follows a normal distribution?
- sample means, thousands of 'em
- a.k.a. Central Limit Theorum
-
- it's OK 'cause sample means will be
- what if n <30? ... (beer is the answer)
-
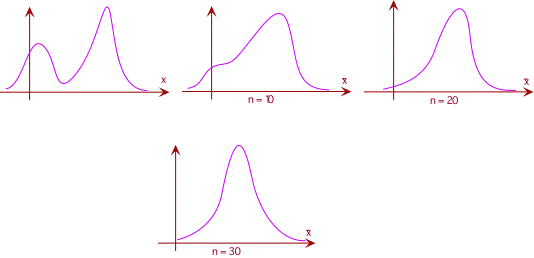
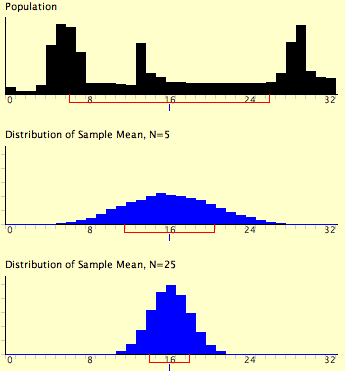
- Middle Aged Spread (or, does this graph make me look fat?)
- shape (distribution)
- pop'n data & sample data
- likely pop'n distr'bns
- skewed
- bimodal
- "strange"
- helps to understand the pop'n
- but usu. not available or considered
-
- follow normal distribution ...
- ... so we use properties of normal (+- 1se = 68%) for large "n"
- ... what about small "n"? (... beer)
- centre
- typically the mean (vs. median or mode)
- THE most important statistic
- spread
- variation
- basic measure is SD
- It's Magic
-
- SD & CV (pop'n)
- SE & SE% (sample)
-
- Finally! ... but is it True?
- What's the diff?
- e.g. consider a small "n" (e.g. 8) ... likelihood of mean = real answer?
- n = 16 ? (i.e. I did 8 more) ...
- n = 2,000 ? ...
- n = 2,008 ?(i.e. I did 8 more) ...
- What happens as more samples taken
- mean
- SD (CV)
- SE (why is this one different?)
- Bias
- biased: SYSTEMATIC error ... final ≠ true
- reasons
- measures (technique, eqpt)
- drunken diameters
- kinked tape
- sample selection
- the closest tree
- the train
- choosing your plot location
- calculation/ improper weighting
- silv survey with concern for roadside
- bias is result, not intent
- How to ensure Final ~ True?
- quality check ("check cruise") ...
- checks for bias (systematic error)
- Accuracy & Precision
- Accuracy
- NO bias
- ... Final = True
- stats give NO clue
- "check cruise"
- Precision
- this IS stats (SE & E)
- a measure of certainty
- I Need a Drink
- ± 1SE ~68%, ± 2 SE ~ 95%
- actually +-2 SE = 95.4%
- +- 1.96 = 95.0%
- +- 1.645 = 90.0%
- beer??
- small sample size? ... ± 1.96 SE = 95% NO longer true

- t distribution
- it's "flatter" and more spread out
- there is a separate curve for each sample size
- for large n we use +/- 2se for 95%
- for small n we use t ... Student's t-table
- ... smaller the n, the bigger the t (or flatter the curve)
- refer to t tables
- magic table - add 3rd column
- sampling error (E)
- it's standard error expressed at a different confidence level
- What does ±15% @ 95% mean??
- 2 parts to statement of certainty
- sampling error (i.e. the 15%)
- confidence level (i.e. the 95%)
- in words ...
- we are 95% sure that ...
- ... the real answer is within 15% of the sample mean
- alternately
- there is a 5% chance that ...
- ... the real answer is actually >15% away from the sample mean
- example
- n = 6, mean = 550sph, se = 30sph
- se% = ?
- e% @90% = ?
- e% @95% = ?
- Sampling Error vs. Confidence Interval
- sampling error as before
- confidence INTERVAL
- really is the "full range" (= mean +- E)
- sometimes expressed as a range (i.e. LCL - UCL)
- survey card is incorrect (CI = E on card)
- example
- n = 6, mean = 550sph, se = 30sph
- E @ 90% in units = ??
- confidence interval = ??
- Assignment
- ave wt of forestry students
- calc: mean, sd, cv, se, se%, t and e (units & %)
- n = 6
- values on board
- hand-in lab when done
- Stop Doing That
- when to stop sampling
- 1) becomes inefficient, extra plots don't help (see graph)
- 2) too expensive, not worth $$/effort to do more
- 3) you already answered the question to your satisfaction
- "good enough for me"
- "you met stats" (or max. plots)
- Meeting Sampling Objective
- max plots done (usu. max plots/ha)
- sampling error (E%) < threshold
- cruising <15% @95% confid.
- silv surveys
- LCL > MSS (... SR)
- X < MSS (... NSR)
- CI < e ... really E < 100sph
- how to ensure enough plots to meet stats ...
- eq'n for sampling error ...
- rearrange for n
- Break It Up
- What (a.k.a. Stratification)
- divide pop'n into homogeneous groups
- each strata is sampled, then ...
- ... the results are combined (inventory & cruising)
- ... the results are kept independent (silv. surveys)
- Why
- reduce variation ... leads to reduced std. error (& less plots)
- better description: separate sub-pop'ns do exist
- isolate a variable (or problem) stratum
- "The Mechanics" (for cruising)
- How to combine strata & get sampling error
- 1) convert SE to total units (i.e. m3, NOT m3/ha nor a %)
- 2) use "Pythagoras theorum" ... A^2 +B^2 = C^2 ... want C
- 3) convert C (i.e. SE combined) to %
- 4) SE% * t = E% ... but t ...
- Data (m3/ha, 1 plot/ha)
- 850 (F)
- 710 (F)
- 476 (FPl)
- 398 (FPl)
- 567 (FPl)
- 974 (F)
- 766 (F)
- 616 (F)
- 630 (FPl)
- stats
- x = 655.2
- sd = 181.0
- se, se%, t & e% ??
- se = 60.3
- se% = 9.2%
- t = 2.306
- e% = 21.2%
- stratified
- F type
- x = 738.2
- sd = 136.5
- se (m3/ha) = ?
- se (total) = ??
- FPl type
- x = 517.8
- sd = 101.8
- se (m3/ha) = ?
- se (total m3) = ??
- combining ...
- SE (total)
- (F) = 61.0 m3/ha * 5ha = 305m3
- (FPl) = 50.8m3/ha * 4ha = 203m3
- Pythagoras
- A^2 + B^2 = C^2
- (305)^2 + (203)^2 = C^2
- C^2 = 134,234
- then sqrt C^2
- C = 366 m3
- this is SE(combined) in units
- want SE(combined) in %
- we have SE in m3
- need total volume in m3
- (738.2 m3/ha * 5ha) + (517.8 m3/ha * 4ha) = total vol. = 5,762.2 m3
- SE% = 366 m3 / 5762.2 m3 = 6.4%
- finally getting E% @ 95%
- t(n-s) = ?
- SE% * t = ?
- Who Cares?
- Number of Plots
- 5 plot minimum per stratum
- maximum density of 1.5 plots/ ha - regardless of stats
- Rule of Thumb for Silv Surveys
- 80% of strata need 10 or less plots
- 15% of strata need 11-25 plots
- 5% may need >25 plots
- Plot Layout
- Grid
- variable strata
- need lotsa plots
- want to "cover the ground"
- stats
- Vector
- odd shaped blocks
- less variable strata
- fewer plots
- stats
- Representative
- obvious stocking status
- few plots done
- you pick the location ... caution!
- skilled & experienced surveyor
- stats
- Visual
- obvious status
- estimate
- skilled & experienced surveyor
- no plots ... no stats
- Filling in the card (FS 1138A)
- Opening - "the block"
- Strata - usually a SU
- Area - important for max. plots
- No. of Plots
- mean (stems per plot & per ha)
- std dev (S)
- std error (Sx)
- t (@90%) n-1
- CI (t* Sx) ... = sampling error
- LCL (x - CI)
- MSS (sph)
- e (precision, <0.5 or 100 sph)
- (new) n
- Decision Rules
- 1) if mean & LCL > MSS ... SR/FG
- 2) if mean < MSS ... NSR/NFG
- 3) if MSS is btwn mean and LCL ... oh crap, gotta think
- a) if CI < e (0.5 or 100 sph), use mean ... SR/FG
- b) if CI > e ... need more plots
- calculate new n
- new n - plots already done = additional plots (to a max of 1.5/ha)
- do the extra plots
- re-calculate mean with extra plots
- compare mean to MSS to decide (no longer look at LCL)
- example (3, 2, 4, 1, 4, 5)
- area = 7 ha, MSS = 500
- End of Survey
- map with table
- SU & stratum
- Area: Gross, NP, NAR
- Status: SR/NSR or FG/NFG
- Inventory Label
- Silviculture Label
- Recomendations